Zur Klassifizierung von Rechenzentren wurde die Tier-Topologie Ende der 1990er Jahre vom Uptime Institut mit Sitz in den USA, weltweit als Standard eingeführt. Jedes „Tier“ (dt. Stufe oder Level) steht für einen bestimmten Rang, den das jeweilige Rechenzentrum bzw. dessen Subsysteme erfüllt. Es ist der am häufigsten, teilweise auch missbräuchlich, verwendete „Standard“, um den Aufbau und die Verfügbarkeit eines Rechenzentrums zu beschreiben.
Die Tier-Topologie sieht insgesamt vier Stufen (Tier 1 bis Tier 4) vor, wobei Tier 1 die am wenigsten zuverlässige Umgebung ist und Tier4 als „hochverfügbar“ eingestuft wird.
Was bedeutet „Hochverfügbarkeit“?
„Der Begriff „Verfügbarkeit“ bezeichnet die Wahrscheinlichkeit, dass ein System zu einem gegebenen Zeitpunkt tatsächlich wie geplant benutzt werden kann.“
(Leitfaden „Betriebssichere Rechenzentren“, Bitcom, Dezember 2013)
Die Verfügbarkeit wird dabei als Verhältnis aus Ausfallzeit (Downtime) und Gesamtzeit eines Systems bemessen:Verfügbarkeit = Uptime / (Downtime + Uptime)
oder
Verfügbarkeit (%) = 1 – Ausfallzeit / (Produktionszeit + Ausfallzeit)
[mk_blockquote style=“quote-style“ font_family=“none“ text_size=“12″ align=“left“ padding=“25″]“Hochverfügbarkeit (abgekürzt auch HA, abgeleitet von engl. high availability) bezeichnet also die Fähigkeit eines Systems, bei Ausfall einer seiner Komponenten einen uneingeschränkten Betrieb zu gewährleisten.“
Andrea Held: Oracle 10g Hochverfügbarkeit
[/mk_blockquote]
Für „Hochverfügbarkeit“ muss die Wahrscheinlichkeit, dass ein System verfügbar ist, über 99,99% liegen. Die jährliche Ausfallzeit muss demnach im Minutenbereich liegen.
Vier-Tier-Topologie zur Klassifizierung von Rechenzentren
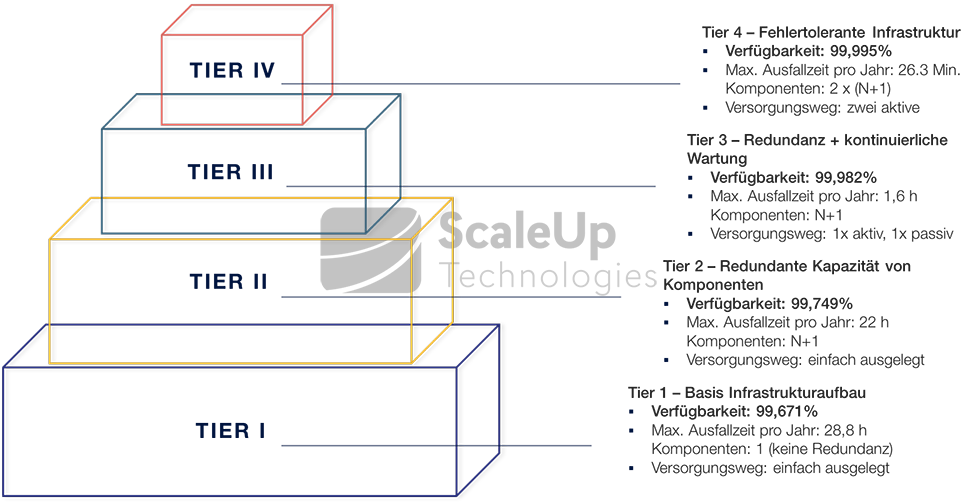
Tier I
Der Tier 1 Standard beschreibt einen Basis-Infrastrukturaufbau, der keine Redundanz umfasst und daher nur für nicht-kritische Workloads (Lasten) geeignet ist. Merkmale sind einfach vorhandene Komponenten zur Versorgung und Verteilung der Lasten. In diesem Aufbaumodell sind Wartungen nur geplant und bei komplett unterbrochenem Betrieb der Systeme möglich. Zudem besteht ein großes Ausfallrisiko, denn Fehler können durch technische Komponenten und durch menschliches Versagen auf allen Anschluss- und Versorgungs-Ebenen auftreten.
Tier II
In einem Tier 2-Rechenzentrum besteht Redundanz durch redundant vorhandene Leistungs- und Kühlungskomponenten („N+1“-Redundanz), wie beispielsweise ein zusätzliches USV-Modul, weitere Kühl-Einheiten, Pumpen oder Generatoren. Der Verteilungspfad für alle Lasten ist jedoch weiterhin einfach ausgelegt, weshalb sich die Verfügbarkeit zwar erhöht aber gegenüber dem folgenden Tier 3 Level deutlich schwächer ausfällt. In diesem Aufbau, der möglicherweise als Übergangslösung gedacht ist, können geplante Maßnahmen und ungeplante Ereignisse die laufenden Systeme immer noch stark beeinträchtigen oder zum Komplett-Ausfall führen.
Tier III
Tier 3 ist der am meisten verwendete Standard. Ein wesentlicher Unterschied zu Tier 2 ist, dass in einem Tier 3 Rechenzentrum „durchgehende Wartung“ möglich ist. Wartungen einzelner Komponenten können planbar, ohne Unterbrechung im laufenden Betrieb vorgenommen werden. Für die Versorgung und Verteilung der Last besteht dafür jeweils „N+1“-Redundanz (Lesen Sie dazu auch unseren Blog-Artikel „Wie funktioniert die redundante Stromversorgung im Rechenzentrum?“). Die maximale Ausfallzeit (im Mittel über 5 Jahre) reduziert sich dadurch auf 1,6h pro Jahr.
Tier IV
Beim derzeitigen Maximal-Level Tier 4 kommen fehlertolerante Infrastruktur-Elemente hinzu. In diesem Aufbau verfügt jedes Systemelement über eigene Automatismen, die bei einem Fehler oder Ausfall einzelner Komponenten automatische Reaktions- und Abwehrmechanismen starten, die diesen entgegenwirken. Alle Kapazitäts- und Versorgungselemente sind zudem durchgängig redundant, und technisch optimal aufeinander abgestimmt angelegt. Komplementäre Systeme und Versorgungspfade werden physisch voneinander isoliert betrieben, um bei Ausfällen „Ansteckungsgefahren“ zu vermeiden. Ein Tier 4-Datacenter gilt mit einer durchnschnittlichen Verfügbarkeit von 99,995% im Jahr als „hochverfügbar“, ist im Aufbau aber sehr komplex und dementsprechend teuer in der Umsetzung.
Fehlertolerante Systeme
Fehlertolerante Systeme erreichen eine besonders hohe Verfügbarkeit, weil sie mithilfe von intelligenter Software auf nahezu alle erdenklichen Fehlerursachen reagieren können. Zusätzlich eliminiert der Aufbau fehlertoleranter Systeme Ursachen für Single Points of Failure (SPOF). Ein SPOF bezeichnet eine einzelne Komponente, die für die korrekte und zuverlässige Funktionsfähigkeit des Gesamtsystems zwingend erforderlich ist. Dies schließt auch das Design des Netzwerkes und der Speichertechnik mit ein: So kann ein ausgefallener Netzwerkswitch bereits dazu führen, dass der Service des Gesamtnetzwerks nicht mehr verfügbar ist.
Durch die Herstellung von Redundanz und automatische Lastenverteilung können SPOF-Risiken eingedämmt werden. Dafür werden die einzelnen Hardware- und Netzwerk-Komponenten wie Router und Switche des selben Typs mehrfach angelegt. Im Falle eines Ausfalls kann die redundante Komponente die Aufgabe der Anderen übernehmen. Bei besonders hohen Verfügbarkeitsanforderungen kann auch die gesamte Rechnerhardware in Form eines Standby-Systems gespiegelt werden.
Es ist jedoch zu beachten, dass eine hohe Verfügbarkeit nicht nur auf physischer Infrastruktur-Ebene bestimmt wird. Die organisatorischen und ausführenden Strukturen sind für einen sicheren Betrieb der Infrastruktur nicht weniger entscheidend. Dazu zählen beispielsweise:
- geschultes Servicepersonal
- Bereithalten von Ersatzteilen
- Abschluss von Wartungsverträgen
- Instruktionen über das Verhalten im Fehler- oder Notfall
- schnelle, exakte Kommunikationsführung
- nachvollziehbare Protokollierung der Ereignisse
Die wichtigsten, zertifizierungsfähigen Normen auf organisatorischer Ebene sind ISO/IEC 27001 (Norm für Information Security Management Systems, kurz ISMS) mit Anlehnung an IT-Grundschutz sowie ISO/IEC 20000 (Norm für IT Service Management, kurz ITSM). Für die Standards ISO/IEC 27001 und ISO/IEC 20000, ist ergänzend auch jeweils ein Leitfaden mit Best Practice Anweisungen vorhanden. Gemeint sind ISO/IEC 27002 und ITIL (IT Infrastructure Library).
Empfohlene Links:


