
Eines der großen Versprechen bei der Verwendung von Kubernetes ist die Fähigkeit, Infrastruktur dynamisch, basierend auf den Benutzeranforderungen zu skalieren (In unserer Einführung sind wir bereits darauf eingegangen). Standardmäßig werden in Kubernetes jedoch keine Instanzen automatisch hinzugefügt oder entfernt. Dazu müssen der Kubernetes Cluster Autoscaler und der Pod Autoscaler als Erweiterungen aktiviert werden. Wie das funktioniert und welche Formen der Skalierung es innerhalb von Clustern gibt, erläutern wir in den folgenden Abschnitten:
- Grundlagen
- Skalierungsebenen: Pod-Layer- & Cluster-Layer-Skalierung
- Was sind Ressourcenanfragen?
- Ressourcenanforderungen und -begrenzungen
- Autoskalierungsfunktionen in Kubernetes
- Kubernetes-Autoskalierung in der Praxis
Im ersten Teil des Artikels geht es um wichtige Grundlagen zur Kubernetes-Autoskalierung: Ebenen der Skalierung, sowie Ressourcenanfragen, -anforderungen und -limits. Im Anschluss gehen wir auf die einzelnen Autoskalierungswerkzeuge bzw. Add-ons für Kubernetes ein (HPA, VPA und Cluster Autoscaler). Der dritte Teil ist dann eine kurze Zusammenfassung mit Empfehlungen für den praktischen Einsatz von Autoskalierung in Kubernetes.
1. Grundlagen
Cluster sind die Art und Weise wie Kubernetes Maschinen in Gruppen anordnet. Cluster bestehen aus Knoten (einzelne Maschinen, meist virtuelle Maschinen), auf denen „Pods“ ausgeführt werden. Ein Pod verfügt wiederum über Container, die Ressourcen wie CPU, Arbeitsspeicher und GPU anfordern (lesen Sie dazu „Die Architektur von Kubernetes“).
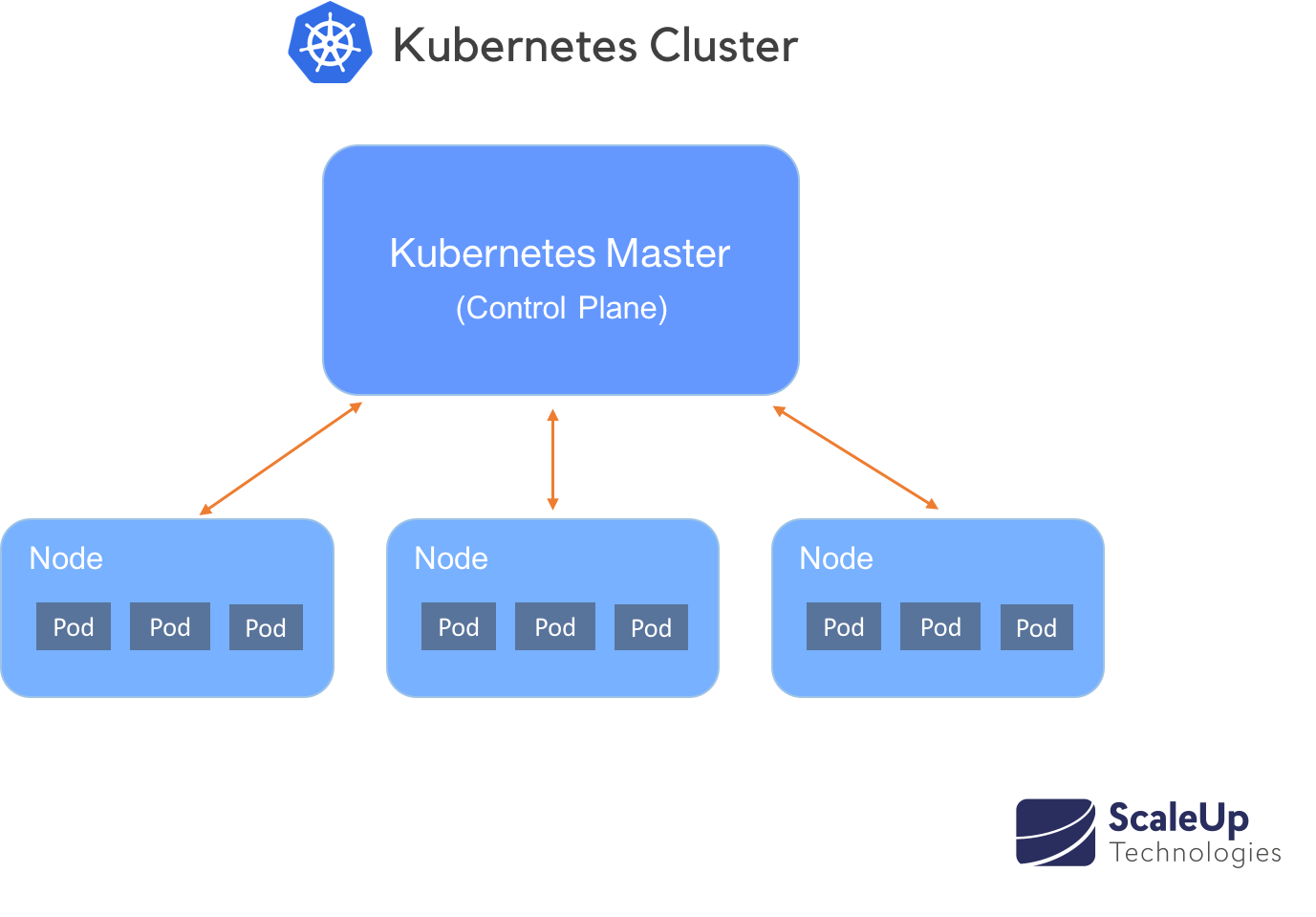
Skalierungsebenen: Pod-Layer- & Cluster-Layerskalierung
Eine effektive Kubernetes-Skalierung erfordert die Koordination zwischen zwei Skalierungsebenen, einmal auf Pod- und einmal auf Cluster-Ebene. Der (1) Pod-Layer-Autoskalierer ermöglicht die Skalierung verfügbarer Ressourcen innerhalb der Container in zwei Richtungen, horizontal und vertikal durch den Horizontalen Pod-Autoskalierer (HPA) und den vertikalen Pod-Autoskalierer (VPA). Der (2) Cluster Autoscaler (CA) vergrößert oder verkleinert hingegen die Anzahl der Knoten (Nodes) innerhalb des Clusters.
Was sind Ressourcenanfragen?
Kurzer Rückblick: Wir erinnern uns an den Kube-Scheduler in der Control Plane. Die Control Plane ist der Master Knoten innerhalb des Kubernetes Clusters. Aufgabe des Kube-Scheduler’s ist es zu entscheiden, wo ein bestimmter Pod ausgeführt werden soll. Gibt es Knoten mit genügend freien Ressourcen, um den Pod auszuführen? Um die Ausführung von Pods effektiv planen zu können, muss der Kube-Scheduler die minimal und maximal zulässigen Ressourcenanforderungen für jeden Pod kennen. Er fragt diese Mindest- und Maximalanforderungen also ab, bevor neue Pods entsprechend ausgeführt werden können.
Kubernetes kennt zwei Arten von Ressourcen, die verwaltet werden: CPU und Speicher (Memory). Es gibt noch weitere Ressourcentypen, die zu Konflikten innerhalb eines Kubernetes Clusters führen können, wie Netzwerkbandbreite, E /A-Vorgänge und Speicherplatz, aber für diese kann Kubernetes zur Zeit noch keine Pod-Anforderungen beschreiben. Da die meisten Pods keine vollständige CPU benötigen, werden Anforderungen und Grenzwerte normalerweise in Millicups (manchmal auch als Millicores) angegeben. Der Speicher wird in Bytes gemessen.
Es besteht außerdem die Möglichkeit, Pods basierend auf benutzerdefinierten Metriken, mehreren Metriken oder sogar auf Basis von externen Metriken (z. B. Fehlerhäufigkeiten innerhalb der App) zu skalieren.
Ressourcenanforderungen
Eine Ressourcenanforderung gibt die Ressourcen-Mindestmenge an, die für die Ausführung des Pods erforderlich ist. Beispielsweise bedeutet eine Ressourcenanforderung von 200 m (200 Millicpus) und 500 MB (500 MiB Speicher), dass der Pod nicht auf einem Knoten mit weniger als den Ressourcen geplant werden kann. Wenn kein Knoten mit ausreichender Kapazität verfügbar ist, bleibt der Pod in einem ausstehenden Zustand, bis diese wieder verfügbar ist.
Ressourcenbegrenzungen /Ressourcenlimits
Ein Ressourcenlimit gibt die maximale Menge an Ressourcen an, die ein Pod verwenden darf. Ein Pod, der versucht, mehr als das zugewiesene CPU-Limit zu verwenden, wird automatisch gedrosselt, was die Leistung verringert. Ein Pod, der versucht, mehr als das erlaubte Speicherlimit zu nutzen, wird beendet. Wenn der terminierte Pod zu einem späteren Zeitpunkt wieder neu zugeordnet werden kann, weil auf demselben oder einem anderen Knoten genügend freie Ressourcen vorhanden sind, wird der Pod wieder neu gestartet.
Wichtig: Mindestanforderungen und Ressourcenlimits lassen sich nur auf Container-Ebene festlegen und sollten mit Bedacht gewählt werden.
2. Autoskalierungsfunktionen in Kubernetes
Auf Container-Ebene können Ressourcen in zwei Richtungen skaliert werden: horizontal durch den Horizontalen Pod-Autoskalierer (HPA) und vertikal durch den vertikalen Pod-Autoskalierer (VPA).
Horizontale Pod Autoskalierung (HPA)
Der Horizontal Pod Autoscaler (HPA) ist als Kubernetes API-Ressource und als Controller bereits implementiert. Ein Replication Controller verwaltet eine bestimmte Anzahl von Pod-Replikas (ein sogenanntes ReplicaSet).
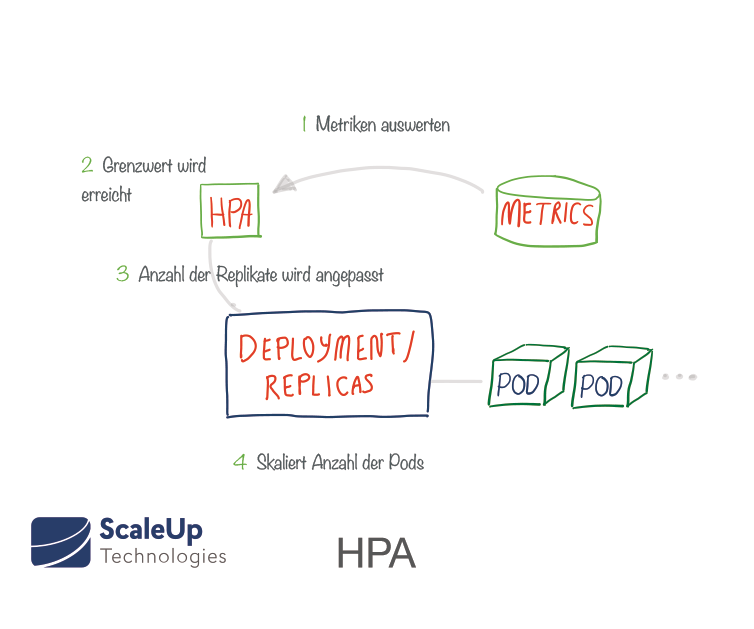
Wenn ein Replika ausfällt, wird ein anderes gestartet, um dieses zu ersetzen. Die Erstellung neuer Pods wird dabei der von Replikas nachgestellt. Die gewünschte Anzahl der Replikate wird im Bereitstellungsmanifest — auf Deployment-Ebene — festgelegt. ReplicaSets ermöglichen die Gruppierung von Pods und enthalten Logiken zu deren Skalierung und lebenszyklische Vorgaben. Durch den Horizontal Pod Autoscaler (HPA) kann Kubernetes die Anzahl der Repliken automatisch an bestimmte Anforderungen anpassen. Der HPA überwacht dafür bestimmte Metriken, um festzustellen, ob die Anzahl der Replikate vergrößert oder verkleinert werden muss. Am häufigsten werden CPU und Speicher als Trigger-Metriken verwendet. Der gemessene Ressourcenstatus bestimmt das Verhalten des Controllers. Der Replication Controller passt die Anzahl der Replikate regelmäßig an, um die beobachtete durchschnittliche CPU-Auslastung an das vom Benutzer angegebene Ziel anzupassen, z.B. wenn eine CPU-Auslastung von 80% angestrebt wird. Wenn die durchschnittliche Auslastung aller vorhandenen Pods in der Bereitstellgung nur 70% der angeforderten Menge beträgt, wird der HPA durch Verringern der Zielzahl von Replikaten die Größe des Deployments verringern. Wenn die durchschnittliche CPU-Auslastung hingegen 90% beträgt und das Ziel von 80% somit überschritten wird, dann wird der HPA weitere Replikate hinzufügen, um die durchschnittliche CPU-Auslastung zu senken.
Vertikale Pod Autoskalierung (VPA)
Der Vertikale Pod Autoscaler (VPA) ist ein relativ neues Kubernetes-Add-On, dass ähnlich wie der HPA arbeitet, jedoch auf Pod-Ebene. Der VPA weist vorhandenen Pods mehr (oder weniger) CPU- / Speicher-Ressourcenanforderungen zu. Er kann somit dabei unterstützen, die idealen Werte für Ressourcenanforderungen zu ermitteln.
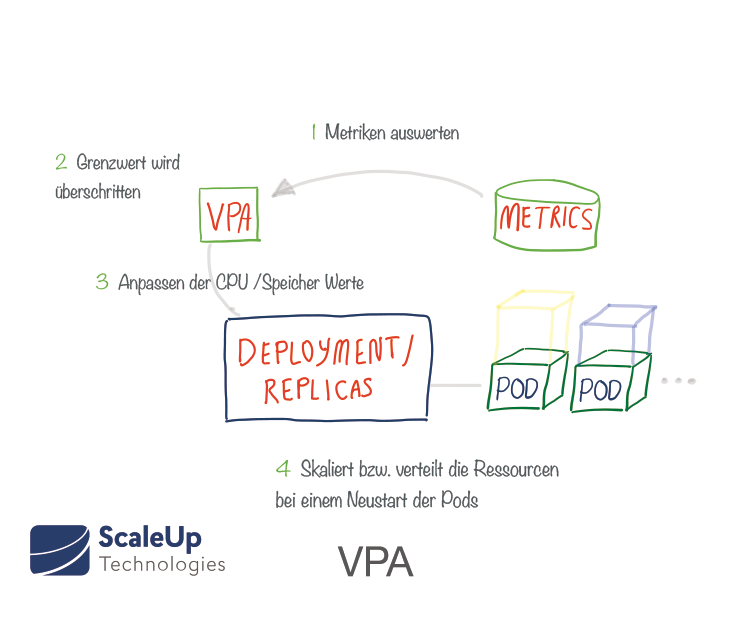
VPA überwacht eine bestimmte Bereitstellung und passt die Ressourcenanforderungen für die Pods automatisch an die tatsächlich verwendeten Anforderungen an. Nach der Anpassung werden die Pods neu gestartet. Er stellt dabei sicher, dass immer die erforderliche Mindestanzahl von Pods vorhanden ist. Es ist außerdem möglich, die minimalen und maximalen Ressourcen festzulegen, die der VPA jedem Pod zuweisen darf . Für den VPA gibt es auch einen Test-Modus (VPA Recommender), der anhand gemessener Metriken und OOM-Events für Anpassungen Vorschläge macht, ohne die laufenden Pods tatsächlich zu modifizieren.
HPA und VPA sind derzeit nur für benutzerdefinierte Metriken kompatibel (nicht für CPU und Memory).
Cluster-Autoskalierer
Cluster Autoscaler (CA) wird jeweils für einen Knotenpool aktiviert. Cluster Autoscaler skaliert Clusterknoten basierend auf ausstehenden Pods. In einem Zeitabstand von 10 Sekunden überprüft der CA, ob ausstehende Pods vorhanden sind, deren Ressourcenanforderungen und prüft, ob die Größe des Clusters erhöht werden muss. CA kommuniziert dann mit dem Cloud-Anbieter, um weitere Knoten anzufordern oder die Zuordnung von inaktiven Knoten aufzuheben. Der Cluster-Autoskalierer fügt in einem Cluster weitere Knoten basierend auf Ressourcenanforderungen von Pods hinzu oder entfernt sie.
Wenn die automatische Skalierung aktiviert ist und anstehende Workloads auf die Verfügbarkeit eines Knotens warten, fügt das System automatisch neue Knoten hinzu, um den Bedarf zu decken.
Cluster Autoscaler berücksichtigt jedoch nicht die von Pods aktiv genutzten Ressourcen, sondern geht davon aus, dass die angegebenen Pod-Ressourcenanforderungen, korrekt sind.
Umgekehrt konsolidiert der Autoscaler bei Kapazitätsreserven die Pods auf einer kleineren Anzahl von Knoten und entfernt die nicht verwendeten Knoten.
3. Kubernetes-Autoskalierung in der Praxis
Wenn Sie einen Pod erstellen, wählt der Kube-Scheduler einen Knoten aus, auf dem der Pod ausgeführt werden soll. Jeder Knoten hat eine maximale Kapazität für CPU und Speicher, die er für Pods bereitstellen kann. Der Scheduler stellt sicher, dass für jeden Ressourcentyp die Summe der Ressourcenanforderungen der geplanten Container kleiner ist als die Kapazität des Knotens. Dabei kann es vorkommen, dass der Scheduler es ablehnt, einen Pod auf einem Knoten zu platzieren, wenn die Kapazitätsprüfung fehlschlägt, obwohl die tatsächliche Speicher- oder CPU-Ressourcennutzung auf Knoten sehr gering ist. Dies schützt vor einer Ressourcenknappheit auf einem Knoten, wenn die Ressourcennutzung volatil ist und später zunehmen kann, z. B. während Leistungspitzen.
Grundsätzlich müssen bei der Autoskalierung Service- und Ressourcenverfügbarkeit gegenüber Performance-Aspekten und natürlich Kosten abgewogen werden. Ein guter Ansatz ist es, die Ressourcengrenzen für einen Container etwas über dem Maximum einzustellen, das er im normalen Betrieb verwendet. Zudem lohnt es sich, die Ressourcenanforderungen und -begrenzungen regelmäßig hinsichtlich ihrer tatsächlichen Nutzung zu prüfen.
Wenn Sie mehr über den praktischen Einsatz von Kubernetes und Autoskalierung erfahren wollen, kontaktieren Sie uns gerne. Sie können Kubernetes bei uns auch 14 Tage angewendet testen, einen unserer Workshops besuchen oder mit uns über Ihre individuellen Anforderungen sprechen.


