Kubernetes ist eine Software, die das Orchestrieren und Überwachen von Microservice-Containern auf der Cluster-, Service-, Pod- und Container-Ebene ermöglicht. Wie in unserem Einführungsartikel erläutert, verbindet Kubernetes (Abk. „K8s“) verschiedene Server zu einem Cluster und orchestriert darüber Ressourcen und Workloads. In diesem Artikel wollen wir nun den Aufbau und die Komponenten eines Kubernetes Clusters genauer betrachten. Unser Artikel gliedert sich in die Abschnitte:
Ein K8s-Cluster besteht als Hauptkomponenten aus mindestens einem Cluster-Master (Control Plane) und mehreren Arbeitsmaschinen, die als Nodes (dt. „Knoten“) bezeichnet werden. Nodes können sich auf einer physischen oder einer virtuellen Maschine befinden. Auf jeder Node befinden sich alle Dienste, die zur Steuerung von Pods notwendig sind.
Das Gehirn des Clusters befindet sich in der Control Plane, in der alle Aufgaben der Cluster-Orchestrierung gemanagt werden.
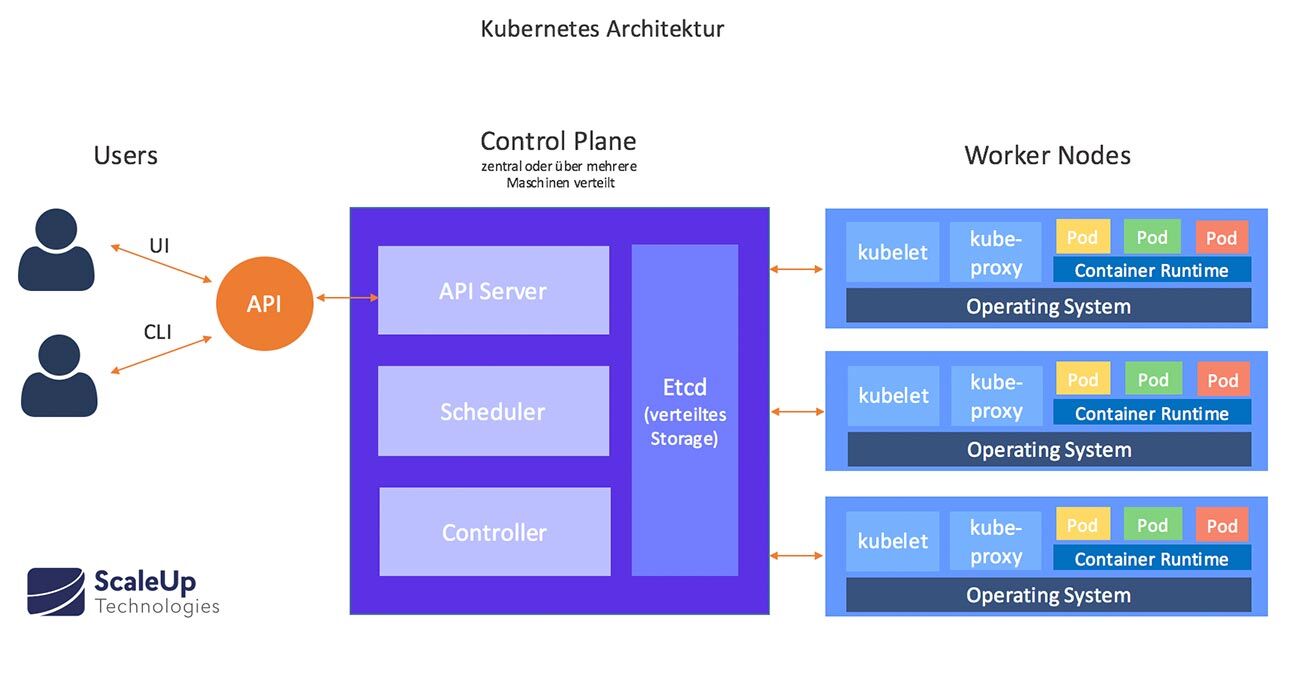
Die Control Plane besteht wiederum aus mehreren Komponenten, den Master Nodes:
Master Nodes
Kube-API-Server
Ist der zentrale Kommunikationsknoten des Clusters. Als Frontend-Server stellt er REST-Endpunkte für die Interaktionen mit anderen Cluster-Komponenten bereit.
Alle Interaktionen mit dem Cluster werden über Kubernetes-API-Aufrufe ausgeführt. Kubernetes-API-Calls können direkt über HTTPs oder indirekt über Befehle im Kubernetes-Command-Line-Client (kubectl) sowie das Kuberndetes-UI (Dashboard) ausgeführt werden.
Etcd
Etcd ist das Datenbank-Backend und enthält Informationen zur Cluster-Konfiguration, also welche Nodes, Ressourcen innerhalb des Clusters verfügbar sind. Auch der Clusterzustand wird im Etcd gespeichert.
Kube-Scheduler
Beobachtet neu erstellte Pods, denen kein Knoten zugewiesen ist, und wählt einen Knoten aus, auf dem sie ausgeführt werden sollen. Zu den zu berücksichtigten Faktoren zählen bspw. individuelle und kollektive Ressourcenanforderungen, Hardware- / Software- / Richtlinieneinschränkungen, Datenstandort sowie Abhängigkeiten zwischen Workloads und Fristen.
Kube-Controller-Manager
Im Kube-Conroller-Manager sind die Hauptsteuerungsschleifen implementiert. Er verwaltet Ressourcen und Deployments, überwacht Unterschiede zwischen dem aktuellen und gewünschten Clusterstatus und führt die erforderliche Änderungen durch, um den gewünschten Status zu erreichen. Eigentlich ist jeder Controller ein separater Prozess. Um die Komplexität zu reduzieren, werden sie jedoch alle zu einer einzigen Binärdatei zusammengefasst und in einem einzigen Prozess ausgeführt.
Controller umfassen:
Node Controller: Verantwortlich für das Erkennen und Reagieren, wenn Knoten ausfallen.
Replication Controller: Verantwortlich für die Aufrechterhaltung der korrekten Anzahl von Pods für jedes Replikationscontroller-Objekt im System.
Endpoint Controller: Füllt das Endpoint-Objekt, welches Services & Pods verbindet.
Service Account und Token Controller: Erstellen Standardkonten und API-Zugriffstoken für neue Namespaces
Cloud-Controller-Manager
Der Cloud-Controller-Manager ist mit dem Cloud-Provider verbunden (in Cloud-basierten Kubernetes-Clustern) und überprüft, ob nicht reagierende Nodes vom Cloud Anbieter gelöscht wurden (per Node Controller), organisiert das Routing über sog. Route Controller, die Ressourcen wie Loadbalancer (Service Controller) und Festplattenspeicher (Volume Controller) verwalten.
Worker Nodes
Worker-Node-Komponenten werden auf jedem Knoten ausgeführt. Sie „pflegen“ sozusagen laufende Pods und bestimmen die Kubernetes-Laufzeitumgebung.
Kubelet
Ein Agent, der auf jedem Knoten im Cluster ausgeführt wird. Ein Kubelet startet die Pods mit der verfügbaren Container-Engine (Docker, rkt usw.) und überprüft / meldet anhand spezifischer PodSpecs regelmäßig den Pod-Status.
Kube-Proxy
Kube-Proxy überprüft Aufrechterhaltung der Netzwerkregeln auf dem Host und führt Verbindungsweiterleitungen an Service-Endpunkten aus.
Container-Runtime
Betreibt die Contianer-Engine. Kubernetes unterstützt mehrere Container-Engines: Docker, containerd, cri-o, rktlet und jede Implementierung des Kubernetes CRI (Container Runtime Interface).
Container brauchen demnach kein eigenes Gast-Betriebssystem, was sie besonders effizient und zeitsparend macht. Jeder Container erhält stattdessen eine eigene dünne Schicht an Betriebssystemfunktionen.
Addons
Kubernetes Komponenten werden durch Addons zusätzlich erweitert. Addons sind Pods und Services, die ein jeweiliges Cluster-Feature bereitstellen. Addons können auf verschiedenen Deployment-Ebenen gemanagt werden. Die hier gelisteten Kubernetes Addons stellen lediglich eine aufgrund ihrer Relevanz gemachte Auswahl dar:
Core-DNS
Core-DNS ist ein interner Cluster-DNS-Server. Er konfiguriert automatisch Register für Kubernetes Namespaces, -Services und Pods. Andere Services im Cluster werden für Pods so einfacher gefunden.
Web-UI
Web-UI (Dashboard) ist eine allgemeine, webbasierte Benutzeroberfläche für Kubernetes-Cluster. Das Kubernetes-Dashboard bietet Funktionen zum Bereitstellen und Überwachen von Anwendungen, die im Cluster ausgeführt werden, sowie zur Fehlerbehebung.
Monitoring Tools für die Ressourcenverwaltung von Containern
Container Resource Monitoring zeichnet generische Zeitreihenmessdaten zu Containern in einer zentralen Datenbank auf und stellt eine Benutzeroberfläche zum Durchsuchen dieser Daten auf Container, Pod, Service und Cluster-Ebene bereit. Diese Daten sind wichtig für den zuverlässigen Betrieb und die automatische Skalierung von Clustern.
In Kubernetes sind verschiedene Monitoring-Lösungen zur Anwendungs-überwachung verfügbar. Standardmäßig sind für neu angelegte Cluster zwei separate Pipelines anwendbar, um Überwachungsstatistiken zu erfassen: Die „Resource Metrics Pipeline“ (Kubelet, cAdvisor) und „Full Metrics Pipeline“ (erfasst deutlich mehr Metriken, z.B. Prometheus).
Cluster Level Logging
Speichert Container-Logfiles in einem zentralen Logspeicher und bietet eine Suche/Browse-Oberfläche.
Es ist sinnvoll, Log-Protokolle unabhängig von Containern und Knoten auf Cluster-Ebene zu speichern, da diese Informationen verloren gehen würden, wenn ein Container oder Knoten abstürzt oder ein ein Pod gelöscht wird.
Für die Protokollierung auf Clusterebene ist ein separates Backend erforderlich, um Protokolle zu speichern, zu analysieren und abzufragen. Kubernetes bietet keine native Speicherlösung für Protokolldaten. Es gibt jedoch viele vorhandene Protokollierungslösungen, die in das Kubernetes-Cluster integriert werden können. Mögliche Lösungsansätze sind:
Node-Level Logging Agents: Laufen auf jeder Node mit,
dedizierter Sidecar-Container für Logging zum Anmelden in einem Anwendungs-Pod oder
Automatisches Verschieben der Anwendungs-Logfiles ins Backend.
Weitere Informationen zum Themenschwerpunkt Logging finden Sie hier: https://kubernetes.io/docs/concepts/cluster-administration/logging/
Kubernetes Cluster Deployment
Ein Kubernetes-Cluster-Deployment erfordert möglicherweise mehrere Master-Nodes und einen separaten Etcd-Cluster, um hohe Verfügbarkeit zu gewährleisten. Kubernetes verwendet zudem ein Overlay-Netzwerk, um Netzwerkfunktionen bereitzustellen, die einer auf einer virtuellen Maschine basierenden Umgebung ähneln. Dieses Software-defined-Network (SDN) ermöglicht die Kommunikation zwischen Containern im gesamten Cluster und stellt eindeutige IP-Adressen für jeden Container bereit.
Fazit
Kubernetes besteht im Prinzip aus einem Satz unabhängiger Kontrollprozesse, die sich wie in einem Lego-Baukasten immer wieder zu neuen Workflows zusammensetzen lassen. Die Kontrollprozesse kontrollieren und verändern fortlaufend den Ist-Zustand der Container-Landschaft und überführen diesen zum Sollzustand. Die Orchestrierung wird somit praktisch verselbstständigt und eine zentrale Kontrollinstanz ist nicht mehr notwendig. Applikationen können durch automatisierte Prozesse schneller und einfacher entwickelt, betrieben und skaliert werden.
Wenn Ihr Interesse an dieser Technologie geweckt ist, können Sie Kubernetes gerne bei uns testen, einen unserer Workshops besuchen oder mit uns über Ihre individuellen Anforderungen sprechen.


