The Uptime Institute, based in the USA, introduced the tier topology as a global standard for classifying data centers at the end of the 1990s. Each "tier" stands for a certain rank that the respective data center or its subsystems fulfill. It is the most commonly used, and sometimes misused, "standard" to describe the structure and availability of a data center.
The tier topology provides for a total of four tiers (Tier 1 through Tier 4), with Tier 1 being the least reliable environment and Tier4 being classified as "highly available."
What does "high availability" mean?
"The term "availability" refers to the probability that a system can actually be used as designed at a given time.“
(Guide "Operationally Secure Data Centers, Bitcom, December 2013)
Availability is measured as the ratio of downtime to total system time: Availability = Uptime / (Downtime + Uptime)
or
Availability (%) = 1 - downtime / (production time + downtime)
[mk_blockquote style="quote-style" font_family="none" text_size="12″ align="left" padding="25″]"High availability (also abbreviated to HA, derived from engl. high availability) thus refers to the ability of a system to ensure unrestricted operation in the event of failure of one of its components."
Andrea Held: Oracle 10g High Availability
[/mk_blockquote]
For "high availability", the probability of a system being available must be above 99.99%. The annual downtime must therefore be in the range of minutes.
Four-tier topology for data center classification
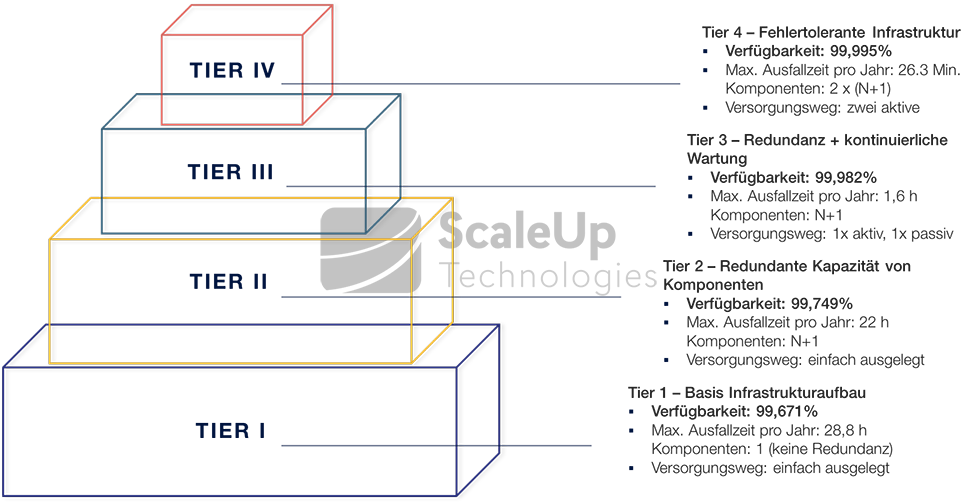
Tier I
The Tier 1 standard describes a basic infrastructure setup that does not include redundancy and is therefore only suitable for non-critical workloads (loads). Features are simply existing components to supply and distribute the loads. In this setup model, maintenance is only possible on a planned basis and when the systems are completely interrupted. In addition, there is a high risk of failure, because faults can occur due to technical components and human error at all connection and supply levels.
Tier II
In a Tier 2 data center, redundancy is provided by redundant power and cooling components ("N+1" redundancy), such as an additional UPS module, further cooling units, pumps or generators. However, the distribution path for all loads is still single, which is why availability increases but is significantly weaker compared to the following Tier 3 level. In this setup, which is possibly intended as a transitional solution, planned measures and unplanned events can still severely affect the running systems or lead to complete failure.
Tier III
Tier 3 is the most widely used standard. A significant difference to Tier 2 is that "continuous maintenance" is possible in a Tier 3 data center. Maintenance of individual components can be planned without interruption during operation. For the supply and distribution of the load, there is "N+1" redundancy in each case for this purpose (read also our blog article "How does redundant power work in the data center?"). The maximum downtime (average over 5 years) is thus reduced to 1.6h per year.
Tier IV
At the current maximum level Tier 4, fault-tolerant infrastructure elements are added. In this setup, each system element has its own automatic mechanisms that start automatic reaction and defense mechanisms to counteract any error or failure of individual components. All capacity and supply elements are also designed to be redundant throughout, and technically optimally coordinated with each other. Complementary systems and supply paths are operated physically isolated from each other to avoid "contagion risks" in the event of failures. With an average availability of 99.995% per year, a Tier 4 data center is considered "highly available", but its design is very complex and correspondingly expensive to implement.
Fault tolerant systems
Fault-tolerant systems achieve particularly high availability because they can react to almost all conceivable causes of error with the help of intelligent software. In addition, the design of fault-tolerant systems eliminates causes for Single Points of Failure (SPOF). An SPOF refers to a single component that is mandatory for the correct and reliable functioning of the overall system. This also includes the design of the network and the storage technology: For example, a failed network switch can already lead to the service of the overall network no longer being available.
Through the production of Redundancy and automatic load balancing, SPOF risks can be contained. For this purpose, the individual hardware and network components such as routers and switches of the same type are created multiple times. In the event of a failure, the redundant component can take over the task of the others. For particularly high availability requirements, the entire computer hardware can also be mirrored in the form of a standby system.
It should be noted, however, that high availability is not only determined at the physical infrastructure level. The organizational and executive structures are no less crucial for secure operation of the infrastructure. These include, for example:
- trained service personnel
- Keeping spare parts ready
- Conclusion of maintenance contracts
- Instructions on how to behave in the event of a fault or emergency
- fast, accurate communication
- Traceable logging of events
The most important standards that can be certified at the organizational level are ISO/IEC 27001 (standard for Information Security Management Systems, ISMS for short) with reference to IT-Grundschutz and ISO/IEC 20000 (standard for IT service management, or ITSM for short). For the ISO/IEC 27001 and ISO/IEC 20000 standards, a guide with best practice instructions is also available. These are ISO/IEC 27002 and ITIL (IT Infrastructure Library).
Recommended links:


